Interpretable-Machine-Learning
第五章 模型无关方法
解释与机器学习模型的分离(相当于模型无关的解释方法)有一些优势(Ribeiro, Singh, and Guestrin 2016^{26})。与模型相关的解释方法相比,模型无关解释方法的最大优势在于它们的灵活性。当解释方法可以应用于任何模型时,机器学习开发人员可以自由地使用他们喜欢的任何机器学习模型。任何建立在机器学习模型可解释性之上的东西,例如图形或用户界面,都将独立于底层机器学习模型。通常,不仅仅是一种机器学习模型,而是许多类型的机器学习模型都被评估来解决一个任务,当从可解释性角度比较模型时,使用模型无关的解释更容易,因为同样的方法可以用于任何类型的模型。
与模型无关的解释方法相比,另一种方法是只使用可解释的模型。这通常有一个很大的缺点,即与其他机器学习模型相比,预测性能会下降,并且将限制在一种模型中。另一种选择是使用特定模型的解释方法。这样做的缺点是,在解释模型时,将受限于一个模型类型,并且很难切换到其他类型的模型。
与模型无关的解释系统的优势包括(Ribeiro, Singh, and Guestrin 2016):
模型灵活性:解释方法可以适用于任何机器学习模型,如随机森林和深度神经网络。
解释灵活性:将不受限于某种形式的解释。在某些情况下,使用线性公式可能是有用的,在另一些情况下,使用表示特征重要性的图可能是有用的。
表示灵活性:解释器应该能够使用不同的特征表示来表征被解释的模型。对于使用词嵌入向量的文本分类器,最好使用单词是否出现作为解释依据。
更大的愿景
让我们从更高的层次来看模型无关的可解释方法。通过收集数据来捕捉世界,通过学习使用机器学习模型预测数据(用于任务)来进一步抽象世界。可解释方法只是另一个帮助人类理解的层面。
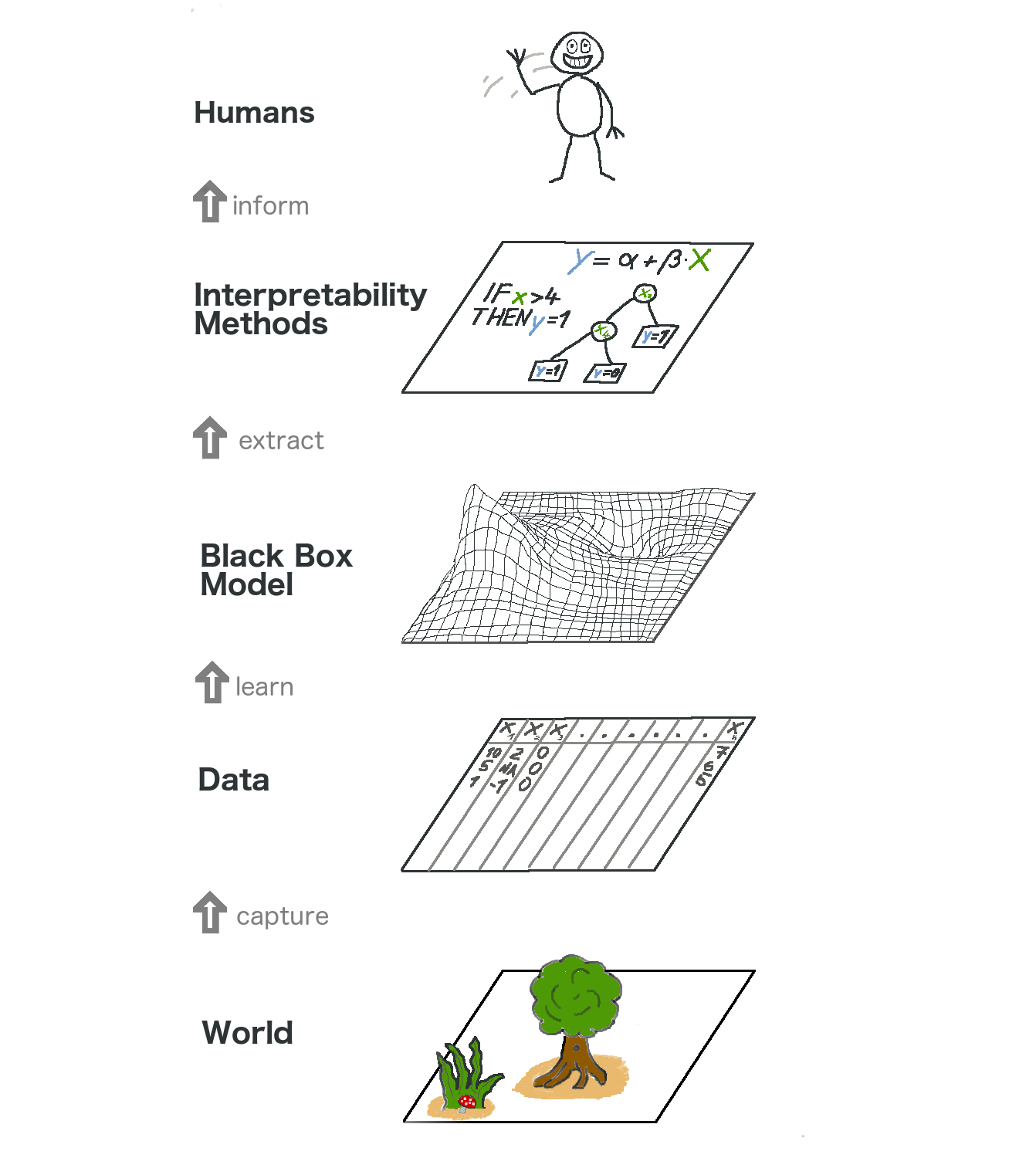
最底层是现实世界。这可以是自然本身,比如人体的生物学,以及它对药物的反应,也可以是更抽象的东西,比如房地产市场。现实世界层包含所有可以观察到和感兴趣的内容。最终,我们试图了解这个世界并与之互动。
第二层是数据层。我们必须把世界数字化,使它可以被计算机处理,也可以存储信息。数据层包含图像、文本、表格数据等等。
第三层是黑盒模型层。它应用机器学习算法,利用现实世界中的数据进行预测或结构发现。
在黑盒模型层之上是可解释性方法层,它帮助我们处理机器学习模型的不透明性:对于一个特定的诊断,最重要的特征是什么?为什么这个金融交易被归类为欺诈?
最后一层由人类占据。看!这个人正向您招手,因为您正在阅读这本书,并帮助为黑匣子模型提供更好的解释!人类最终是解释的消费者。
这种多层抽象还有助于理解统计学家和机器学习实践者之间方法的差异。统计人员处理数据层,例如规划临床试验或设计调查。它们跳过黑盒模型层,直接进入可解释性方法层。机器学习专家还处理数据层,例如收集标记的皮肤癌图像样本或用爬虫抓取维基百科的内容。然后他们训练一个黑盒机器学习模型。可解释方法层被跳过,人类直接处理黑盒模型的预测结果。而最棒的是可解释机器学习融合了统计学家和机器学习专家的工作。
当然,这张图并不能捕捉到所有信息:数据可能是通过模拟得到的。黑盒模型输出的预测结果甚至可能无法触达人类,而只是提供给其他机器,等等。但总的来说,理解可解释性如何成为机器学习模型之上的新层是一个有用的抽象。
Ribeiro, Singh, and Guestrin。与模型无关的机器学习解释能力。“机器学习中的人类解释能力”ICML研讨会。(2016)。