Interpretable-Machine-Learning
名词解释
为了避免含糊不清造成混淆,以下是本书中使用的一些术语的定义:
算法是机器为达到特定目标而遵循的一组规则。算法可以被看作是一个配方,它定义了输入、输出以及从输入到输出所需的所有步骤。烹饪食谱是算法,配料是输入,食物是输出,准备和烹饪步骤是算法指令。
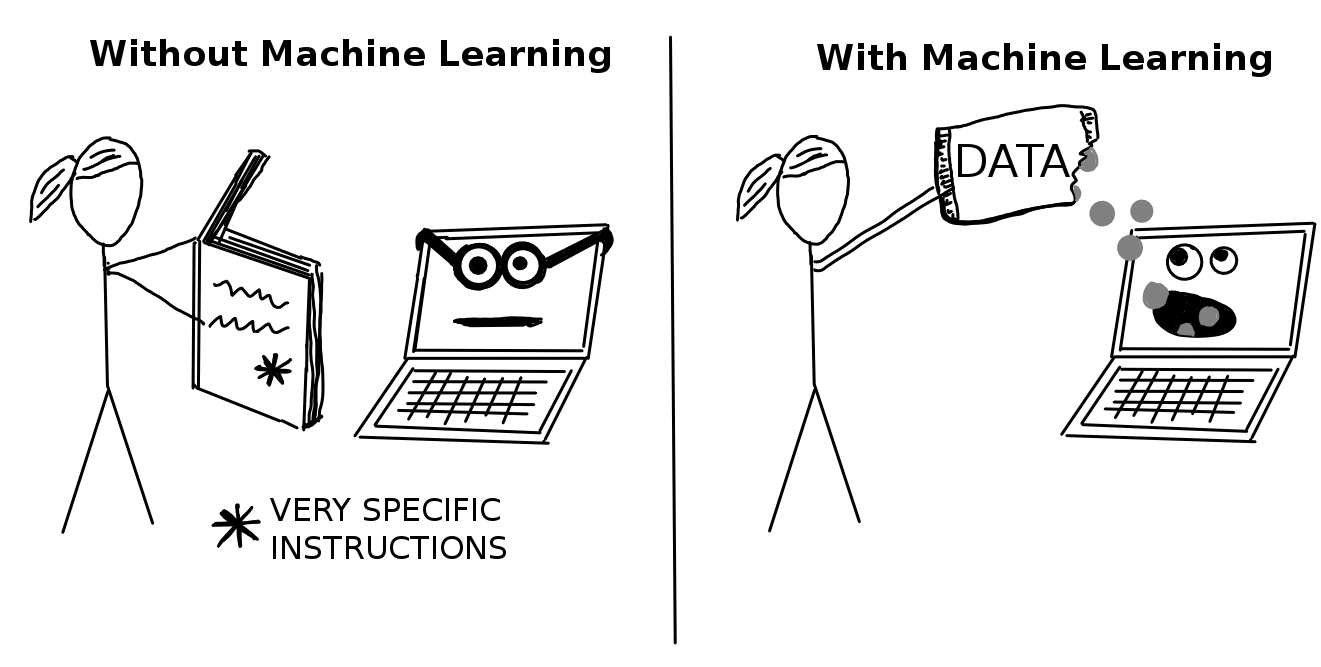
机器学习是一组方法,它允许计算机从数据中学习,从而做出和改进预测(例如癌症预测、每周销售额预测、信用违约预测)。机器学习是一种范式转换,从所有指令都必须明确地交给计算机的“常规编程”,转向通过提供数据进行的“间接编程”。
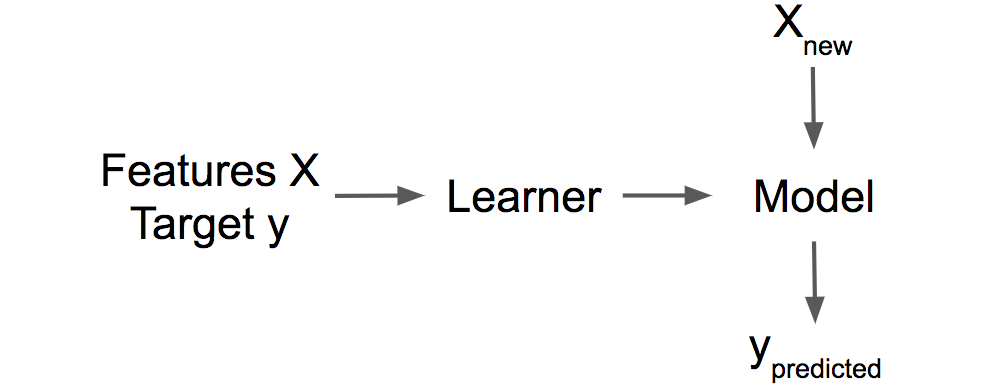
学习器或机器学习算法是从数据中学习机器学习模型的程序。它的另一个名称是“诱导器”(例如“树诱导器”)。
机器学习模型是将输入映射到预测结果的学习程序。这可以是线性模型或神经网络的一组权重。“模型”相对比较晦涩,它的其他名称是“预测器”或(取决于任务)“分类器”或“回归模型”。在公式中,将训练好的机器学习模型称为。
黑盒模型是一个内部处理机制不透明的系统。在机器学习中,“黑盒”描述的模型无法通过查看参数(例如神经网络)来理解。黑盒的反义词有时称为白盒,在本书中称为可解释模型。模型无关的可解释性方法将所有机器学习模型统一视为黑盒模型。
可解释机器学习是指使机器学习系统的行为和预测能够被人类理解的方法和模型。
数据集是一个包含机器从中学习的数据的表。数据集包含要预测的特性和目标。当用于归纳模型时,该数据集称为训练数据。
实例是数据集中的一行。“实例”的其他名称是:(数据)点、示例、观察点。实例由特征值 \(x^{(i)}\) 和目标输出\(y_i\)组成。
特征是用于预测或分类的输入。特性是数据集中的列。在整本书中,特征都被假定是可解释的,这意味着很容易理解它们的含义,比如某一天的温度或一个人的身高。特性的可解释性是一个很强的假设。但是,如果很难理解输入的特征,则更难理解模型的原理。具有所有特征的矩阵称为 \(X\) ,并且 \(x^{(i)}\) 视为单个样本。所有样本的单个特征是\(x_j\),并且第\(i\)个样本第\(j\)个特征是\(x^{(i)}_j\)。
目标是机器学习预测的信息。在数学公式中,对单个样本而言,预测目标通常称为\(y\)或\(y_i\) 。
机器学习任务是具有特征和目标的数据集的组合。根据目标的类型,任务可以是分类、回归、生存分析、聚类或异常值检测。
预测是机器学习模型根据给定的特征“猜测”目标值应该是什么。在本书中,模型预测用\(\hat y\) 或 \(\hat f(x^{(i)})\) 表示。
”算法的定义。“https://www.merriam-webster.com/dictionary/algorithm。(2017)